




Notebooks

Categories



Cells
Notebook
Premium

BioTuring
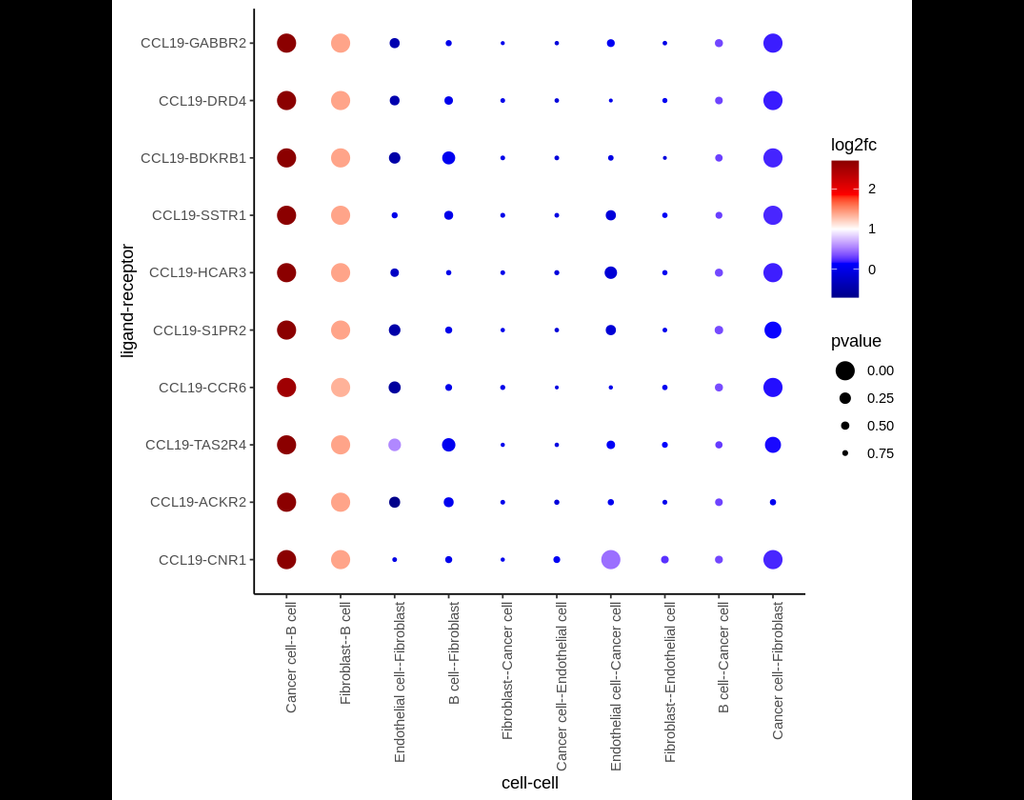
Single-cell RNA data allows cell-cell communications (***CCC***) methods to infer CCC at either the individual cell or cell cluster/cell type level, but physical distances between cells are not preserved Almet, Axel A., et al., (2021). On the other hand, spatial data provides spatial distances between cells, but single-cell or gene resolution is potentially lost. Therefore, integrating two types of data in a proper manner can complement their strengths and limitations, from that improve CCC analysis.
In this pipeline, we analyze CCC on Visium data with single-cell data as a reference. The pipeline includes 4 sub-notebooks as following
01-deconvolution: This step involves deconvolution and cell type annotation for Visium data, with cell type information obtained from a relevant single-cell dataset. The deconvolution method is SpatialDWLS which is integrated in Giotto package.
02-giotto: performs spatial based CCC and expression based CCC on Visium data using Giotto method.
03-nichenet: performs spatial based CCC and expression based CCC on Visium data using NicheNet method.
04-visualization: visualizes CCC results obtained from Giotto and NicheNet.
BioTuring
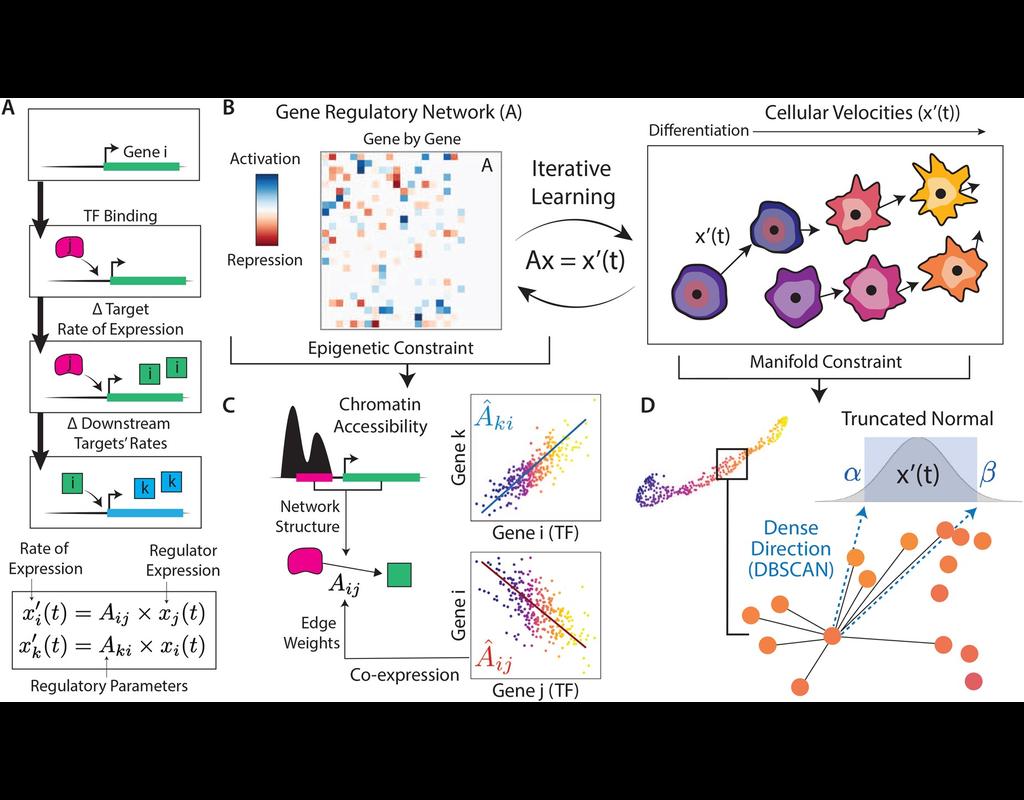
In the realm of transcriptional dynamics, understanding the intricate interplay of regulatory proteins is crucial for deciphering processes ranging from normal development to disease progression. However, traditional RNA velocity methods often overlook the underlying regulatory drivers of gene expression changes over time. This gap in knowledge hinders our ability to unravel the mechanistic intricacies of these dynamic processes.
scKINETICs (Key regulatory Interaction NETwork for Inferring Cell Speed) (Burdziak et al, 2023) offers a dynamic model for gene expression changes that simultaneously learns per-cell transcriptional velocities and a governing gene regulatory network. By employing an expectation-maximization approach, scKINETICS quantifies the impact of each regulatory element on its target genes, incorporating insights from epigenetic data, gene-gene coexpression patterns and constraints dictated by the phenotypic manifold.
BioTuring
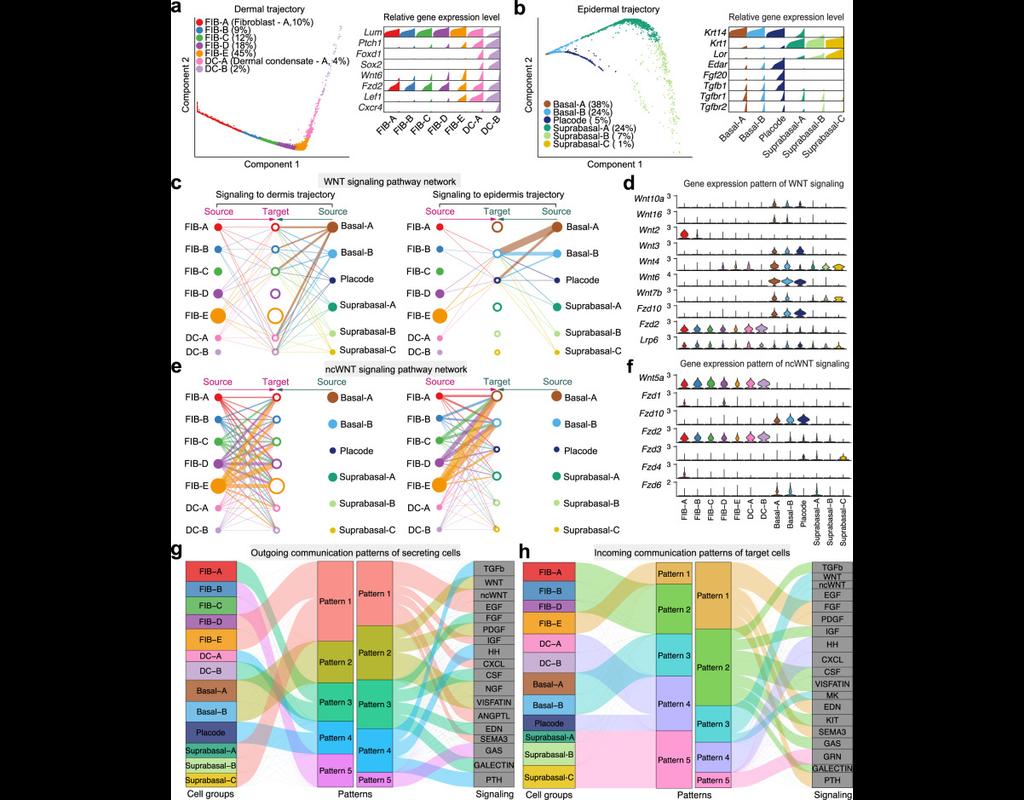
Understanding global communications among cells requires accurate representation of cell-cell signaling links and effective systems-level analyses of those links.
We construct a database of interactions among ligands, receptors and their cofactors that accurately represent known heteromeric molecular complexes. We then develop **CellChat**, a tool that is able to quantitatively infer and analyze intercellular communication networks from single-cell RNA-sequencing (scRNA-seq) data.
CellChat predicts major signaling inputs and outputs for cells and how those cells and signals coordinate for functions using network analysis and pattern recognition approaches. Through manifold learning and quantitative contrasts, CellChat classifies signaling pathways and delineates conserved and context-specific pathways across different datasets.
Applying **CellChat** to mouse and human skin datasets shows its ability to extract complex signaling patterns.
BioTuring
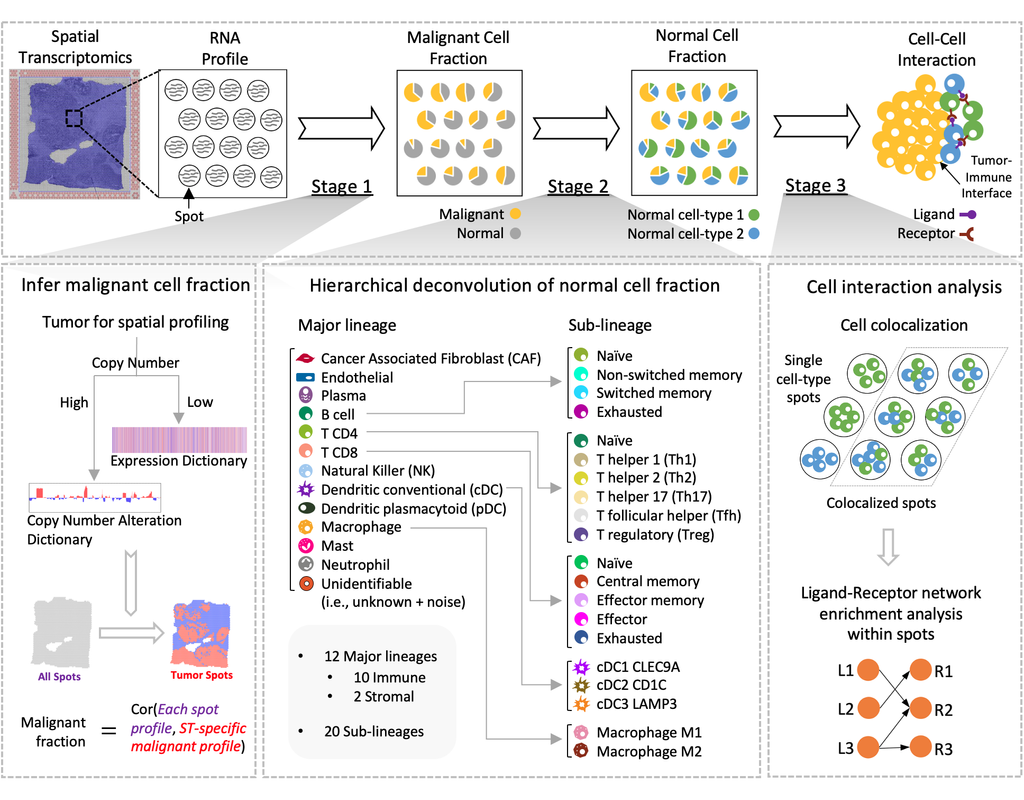
Spatial transcriptomics (ST) technology has allowed to capture of topographical gene expression profiling of tumor tissues, but single-cell resolution is potentially lost. Identifying cell identities in ST datasets from tumors or other samples remains challenging for existing cell-type deconvolution methods.
Spatial Cellular Estimator for Tumors (SpaCET) is an R package for analyzing cancer ST datasets to estimate cell lineages and intercellular interactions in the tumor microenvironment. Generally, SpaCET infers the malignant cell fraction through a gene pattern dictionary, then calibrates local cell densities and determines immune and stromal cell lineage fractions using a constrained regression model. Finally, the method can reveal putative cell-cell interactions in the tumor microenvironment.
In this notebook, we will illustrate an example workflow for cell type deconvolution and interaction analysis on breast cancer ST data from 10X Visium. The notebook is inspired by SpaCET's vignettes and modified to demonstrate how the tool works on BioTuring's platform.