




Notebooks

Categories



Cells
Premium

BioTuring
Cell2location is a principled Bayesian model that can resolve fine-grained cell types in spatial transcriptomic data and create comprehensive cellular maps of diverse tissues. Cell2location accounts for technical sources of variation and borrows statistical strength across locations, thereby enabling the integration of single cell and spatial transcriptomics with higher sensitivity and resolution than existing tools. This is achieved by estimating which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).
This tutorial shows how to use cell2location method for spatially resolving fine-grained cell types by integrating 10X Visium data with scRNA-seq reference of cell types. Cell2location is a principled Bayesian model that estimates which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).
BioTuring
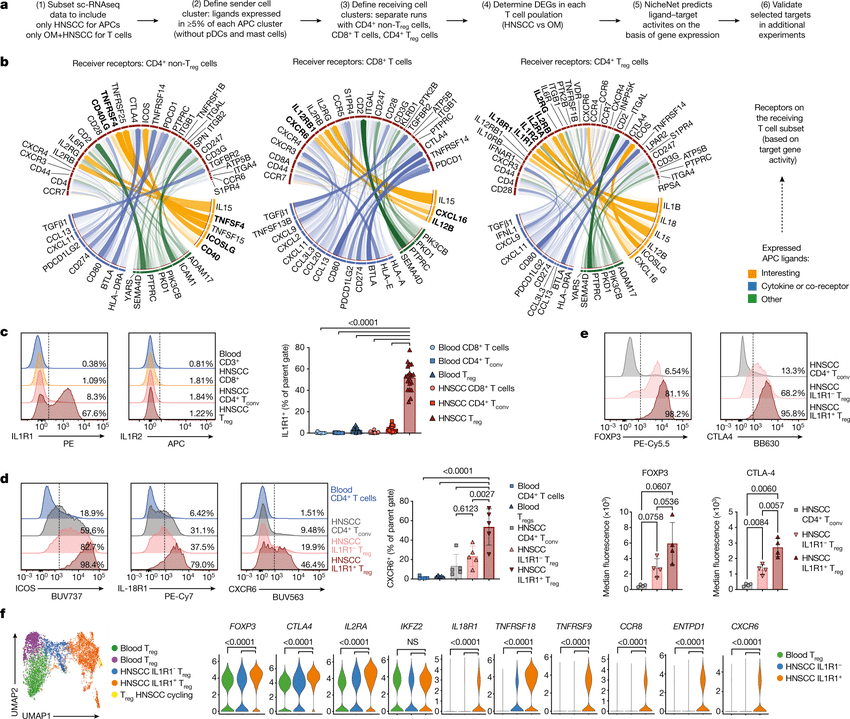
Computational methods that model how the gene expression of a cell is influenced by interacting cells are lacking.
We present NicheNet, a method that predicts ligand–target links between interacting cells by combining their expression data with prior knowledge of signaling and gene regulatory networks.
We applied NicheNet to the tumor and immune cell microenvironment data and demonstrated that NicheNet can infer active ligands and their gene regulatory effects on interacting cells.

BioTuring
In this notebook, we present COMMOT (COMMunication analysis by Optimal Transport) to infer cell-cell communication (CCC) in spatial transcriptomic, a package that infers CCC by simultaneously considering numerous ligand–receptor pairs for either spatial transcriptomic data or spatially annotated scRNA-seq data equipped with spatial distances between cells estimated from paired spatial imaging data.
A collective optimal transport method is developed to handle complex molecular interactions and spatial constraints. Furthermore, we introduce downstream analysis tools to infer spatial signaling directionality and genes regulated by signaling using machine learning models.

BioTuring
CellRank2 (Weiler et al, 2023) is a powerful framework for studying cellular fate using single-cell RNA sequencing data. It can handle millions of cells and different data types efficiently. This tool can identify cell fate and probabilities across various data sets. It also allows for analyzing transitions over time and uncovering key genes in developmental processes. Additionally, CellRank2 estimates cell-specific transcription and degradation rates, aiding in understanding differentiation trajectories and regulatory mechanisms.
In this notebook, we will use a primary tumor sample of patient T71 from the dataset GSE137804 (Dong R. et al, 2020) as an example. We have performed RNA-velocity analysis and pseudotime calculation on this dataset in scVelo (Bergen et al, 2020) notebook. The output will be then loaded into this CellRank2 notebook for further analysis.
This notebook is based on the tutorial provided on CellRank2 documentation. We have modified the notebook and changed the input data to show how the tool works on BioTuring's platform.
Trends

BioTuring
scPRINT is a large transformer model built for the inference of gene networks (connections between genes explaining the cell's expression profile) from scRNAseq data.
It uses novel encoding and decoding of the cell expression profile and new pre-t(More)