




Notebooks

Categories



Cells
Premium

BioTuring
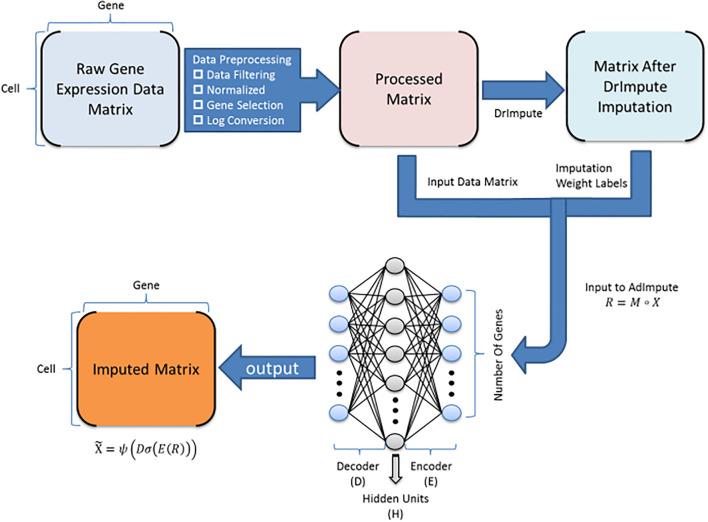
Single-cell RNA sequencing (scRNA-seq) protocols often face challenges in measuring the expression of all genes within a cell due to various factors, such as technical noise, the sensitivity of scRNA-seq techniques, or sample quality. This limitation gives rise to a need for the prediction of unmeasured gene expression values (also known as dropout imputation) from scRNA-seq data.
ADImpute (Leote A, 2023) is an R package combining several dropout imputation methods, including two existing methods (DrImpute, SAVER), two novel implementations: Network, a gene regulatory network-based approach using gene-gene relationships learned from external data, and Baseline, a method corresponding to a sample-wide average..
This notebook is to illustrate an example workflow of ADImpute on sample datasets loaded from the package. The notebook content is inspired from ADImpute's vignette and modified to demonstrate how the tool works on BioTuring's platform.

BioTuring
Single-cell RNA-seq datasets in diverse biological and clinical conditions provide great opportunities for the full transcriptional characterization of cell types.
However, the integration of these datasets is challeging as they remain biological and techinical differences. **Harmony** is an algorithm allowing fast, sensitive and accurate single-cell data integration.

BioTuring
CellRank2 (Weiler et al, 2023) is a powerful framework for studying cellular fate using single-cell RNA sequencing data. It can handle millions of cells and different data types efficiently. This tool can identify cell fate and probabilities across various data sets. It also allows for analyzing transitions over time and uncovering key genes in developmental processes. Additionally, CellRank2 estimates cell-specific transcription and degradation rates, aiding in understanding differentiation trajectories and regulatory mechanisms.
In this notebook, we will use a primary tumor sample of patient T71 from the dataset GSE137804 (Dong R. et al, 2020) as an example. We have performed RNA-velocity analysis and pseudotime calculation on this dataset in scVelo (Bergen et al, 2020) notebook. The output will be then loaded into this CellRank2 notebook for further analysis.
This notebook is based on the tutorial provided on CellRank2 documentation. We have modified the notebook and changed the input data to show how the tool works on BioTuring's platform.
BioTuring
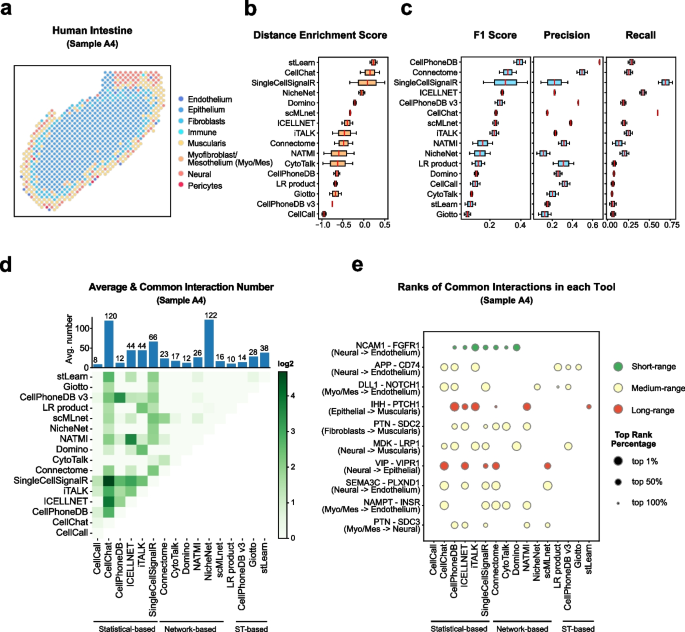
Cell–cell communication mediated by ligand–receptor complexes is critical to coordinating diverse biological processes, such as development, differentiation and inflammation.
To investigate how the context-dependent crosstalk of different cell types enables physiological processes to proceed, we developed CellPhoneDB, a novel repository of ligands, receptors and their interactions. In contrast to other repositories, our database takes into account the subunit architecture of both ligands and receptors, representing heteromeric complexes accurately.
We integrated our resource with a statistical framework that predicts enriched cellular interactions between two cell types from single-cell transcriptomics data. Here, we outline the structure and content of our repository, provide procedures for inferring cell–cell communication networks from single-cell RNA sequencing data and present a practical step-by-step guide to help implement the protocol.
CellPhoneDB v.2.0 is an updated version of our resource that incorporates additional functionalities to enable users to introduce new interacting molecules and reduces the time and resources needed to interrogate large datasets.
CellPhoneDB v.2.0 is publicly available, both as code and as a user-friendly web interface; it can be used by both experts and researchers with little experience in computational genomics.
In our protocol, we demonstrate how to evaluate meaningful biological interactions with CellPhoneDB v.2.0 using published datasets. This protocol typically takes ~2 h to complete, from installation to statistical analysis and visualization, for a dataset of ~10 GB, 10,000 cells and 19 cell types, and using five threads.
Trends
BioTuring
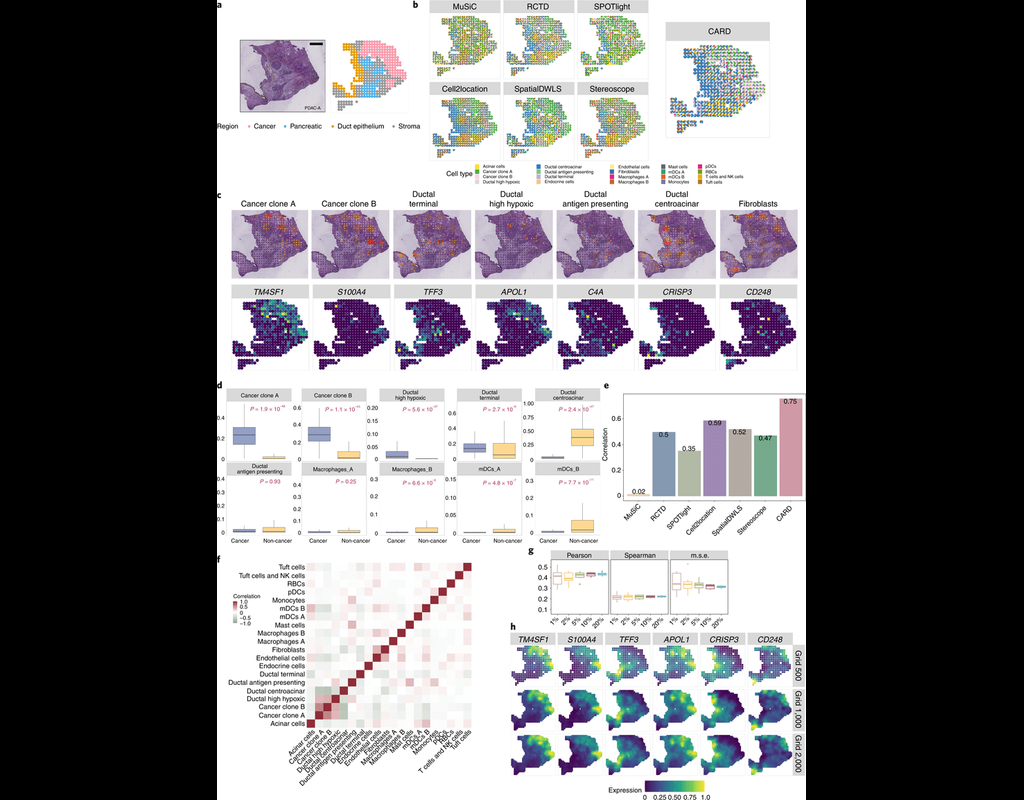
Many spatially resolved transcriptomic technologies do not have single-cell resolution but measure the average gene expression for each spot from a mixture of cells of potentially heterogeneous cell types.
Here, we introduce a deconvolution metho(More)