




Notebooks

Categories



Cells
Premium

BioTuring
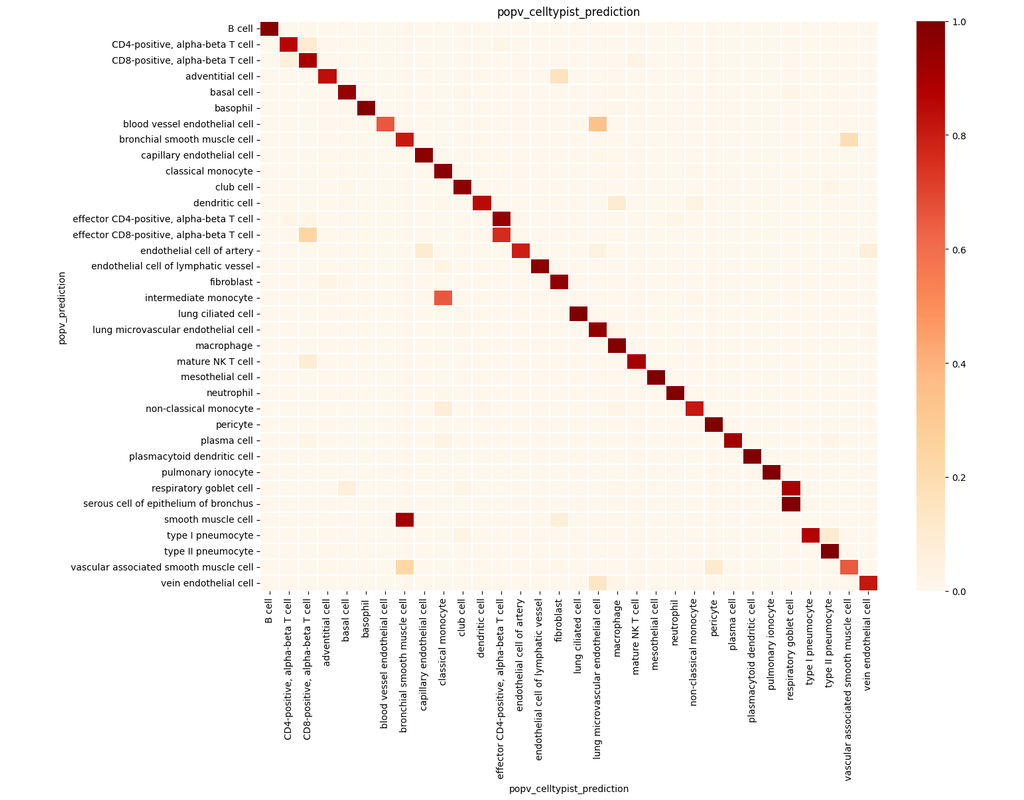
PopV uses popular vote of a variety of cell-type transfer tools to classify cell-types in a query dataset based on a test dataset.
Using this variety of algorithms, they compute the agreement between those algorithms and use this agreement to predict which cell-types have a high likelihood of the same cell-types observed in the reference.
BioTuring
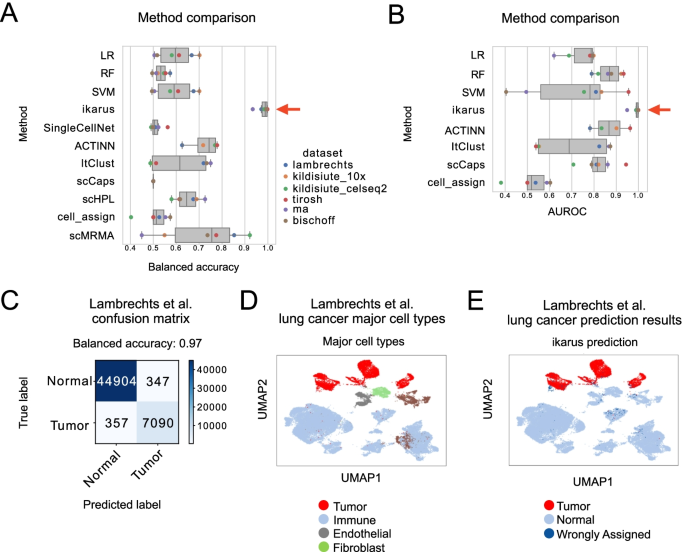
Tumors are complex tissues of cancerous cells surrounded by a heterogeneous cellular microenvironment with which they interact. Single-cell sequencing enables molecular characterization of single cells within the tumor. However, cell annotation—the assignment of cell type or cell state to each sequenced cell—is a challenge, especially identifying tumor cells within single-cell or spatial sequencing experiments.
Here, we propose ikarus, a machine learning pipeline aimed at distinguishing tumor cells from normal cells at the single-cell level. We test ikarus on multiple single-cell datasets, showing that it achieves high sensitivity and specificity in multiple experimental contexts.
**InferCNV** is a Bayesian method, which agglomerates the expression signal of genomically adjointed genes to ascertain whether there is a gain or loss of a certain larger genomic segment. We have used **inferCNV** to call copy number variations in all samples used in the manuscript.
BioTuring
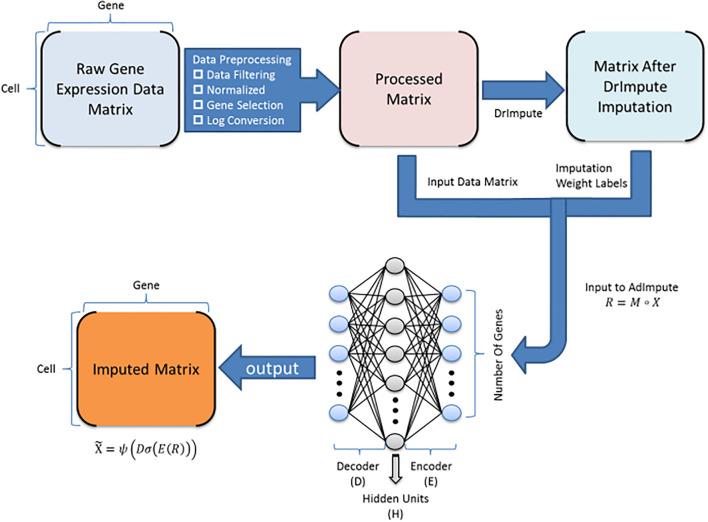
Single-cell RNA sequencing (scRNA-seq) protocols often face challenges in measuring the expression of all genes within a cell due to various factors, such as technical noise, the sensitivity of scRNA-seq techniques, or sample quality. This limitation gives rise to a need for the prediction of unmeasured gene expression values (also known as dropout imputation) from scRNA-seq data.
ADImpute (Leote A, 2023) is an R package combining several dropout imputation methods, including two existing methods (DrImpute, SAVER), two novel implementations: Network, a gene regulatory network-based approach using gene-gene relationships learned from external data, and Baseline, a method corresponding to a sample-wide average..
This notebook is to illustrate an example workflow of ADImpute on sample datasets loaded from the package. The notebook content is inspired from ADImpute's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
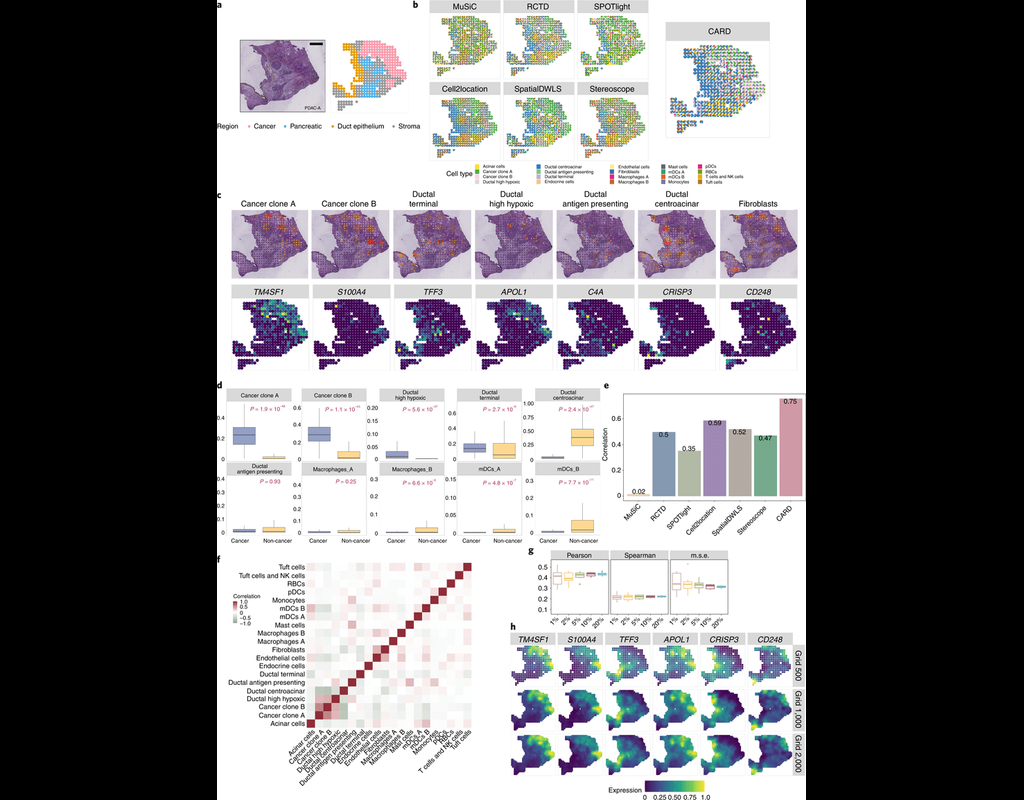
Many spatially resolved transcriptomic technologies do not have single-cell resolution but measure the average gene expression for each spot from a mixture of cells of potentially heterogeneous cell types.
Here, we introduce a deconvolution method, conditional autoregressive-based deconvolution (CARD), that combines cell-type-specific expression information from single-cell RNA sequencing (scRNA-seq) with correlation in cell-type composition across tissue locations. Modeling spatial correlation allows us to borrow the cell-type composition information across locations, improving accuracy of deconvolution even with a mismatched scRNA-seq reference.
**CARD** can also impute cell-type compositions and gene expression levels at unmeasured tissue locations to enable the construction of a refined spatial tissue map with a resolution arbitrarily higher than that measured in the original study and can perform deconvolution without an scRNA-seq reference.
Applications to four datasets, including a pancreatic cancer dataset, identified multiple cell types and molecular markers with distinct spatial localization that define the progression, heterogeneity and compartmentalization of pancreatic cancer.
Trends
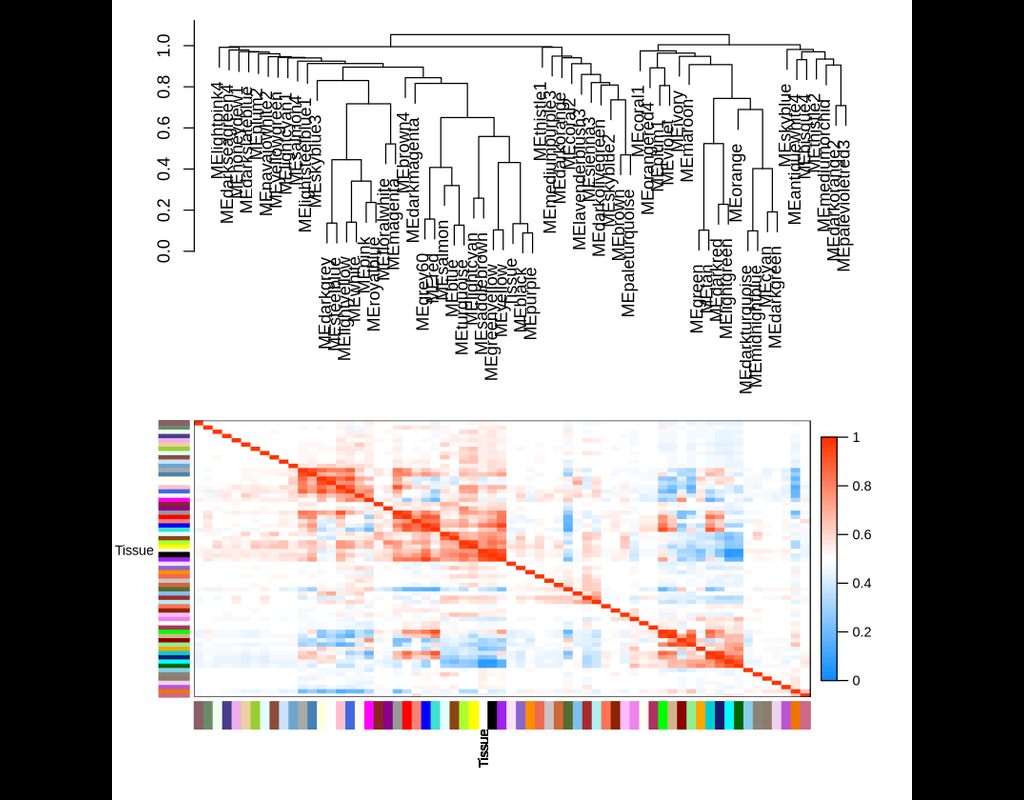
BioTuring
WGCNA: an R package for Weighted Gene Correlation Network Analysis
Correlation networks are increasingly being used in bioinformatics applications. For example, weighted gene co-expression network analysis is a systems biology method for describing (More)