




Notebooks

Categories



Cells
Premium

BioTuring
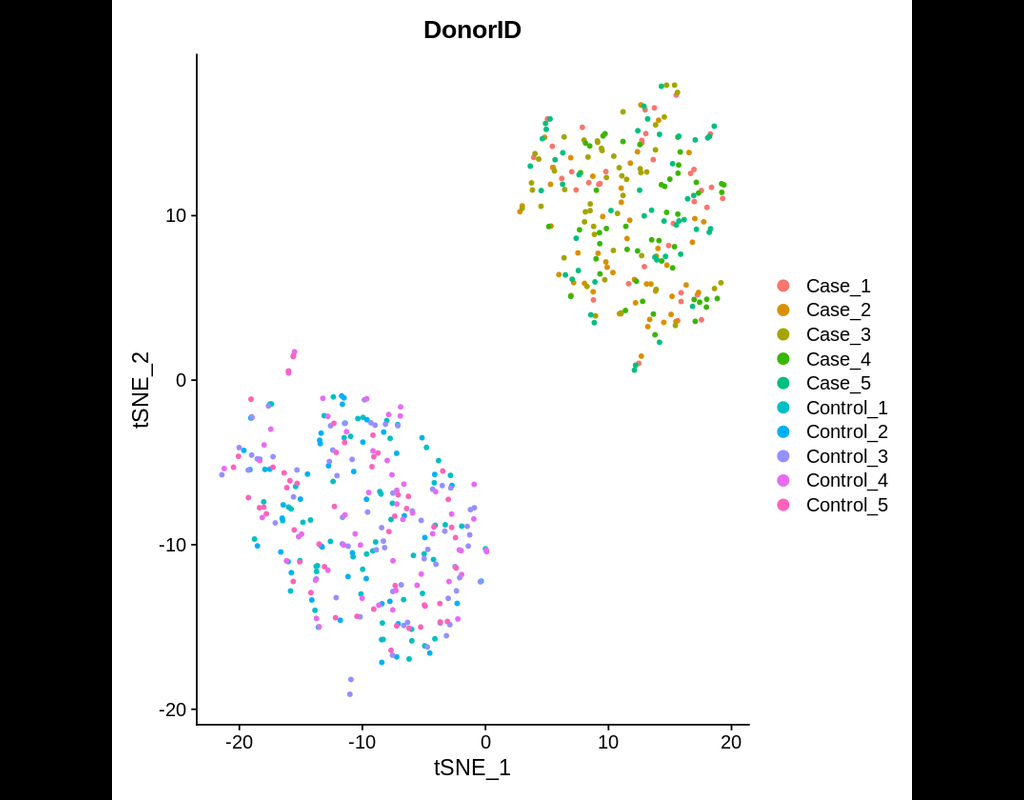
Power analyses are considered important factors in designing high-quality experiments. However, such analyses remain a challenge in single-cell RNA-seq studies due to the presence of hierarchical structure within the data (Zimmerman et al., 2021). As cells sampled from the same individual share genetic and environmental backgrounds, these cells are more correlated than cells sampled from different individuals. Currently, most power analyses and hypothesis tests (e.g., differential expression) in scRNA-seq data treat cells as if they were independent, thus ignoring the intra-sample correlation, which could lead to incorrect inferences.
Hierarchicell (Zimmerman, K.D. and Langefeld, C.D., 2021) is an R package proposed to estimate power for testing hypotheses of differential expression in scRNA-seq data while considering the hierarchical correlation structure that exists in the data. The method offers four important categories of functions: data loading and cleaning, empirical estimation of distributions, simulating expression data, and computing type 1 error or power.
In this notebook, we will illustrate an example workflow of Hierarchicell. The notebook is inspired by Hierarchicell's vignette and modified to demonstrate how the tool works on BioTuring's platform.

BioTuring
The recent development of experimental methods for measuring chromatin state at single-cell resolution has created a need for computational tools capable of analyzing these datasets. Here we developed Signac, a framework for the analysis of single-cell chromatin data, as an extension of the Seurat R toolkit for single-cell multimodal analysis.
**Signac** enables an end-to-end analysis of single-cell chromatin data, including peak calling, quantification, quality control, dimension reduction, clustering, integration with single-cell gene expression datasets, DNA motif analysis, and interactive visualization.
Furthermore, Signac facilitates the analysis of multimodal single-cell chromatin data, including datasets that co-assay DNA accessibility with gene expression, protein abundance, and mitochondrial genotype. We demonstrate scaling of the Signac framework to datasets containing over 700,000 cells.

BioTuring
Single-cell RNA sequencing methods can profile the transcriptomes of single cells but cannot preserve spatial information. Conversely, spatial transcriptomics assays can profile spatial regions in tissue sections but do not have single-cell resolution.
Here, Runmin Wei (Siyuan He, Shanshan Bai, Emi Sei, Min Hu, Alastair Thompson, Ken Chen, Savitri Krishnamurthy & Nicholas E. Navin) developed a computational method called CellTrek that combines these two datasets to achieve single-cell spatial mapping through coembedding and metric learning approaches. They benchmarked CellTrek using simulation and in situ hybridization datasets, which demonstrated its accuracy and robustness.
They then applied CellTrek to existing mouse brain and kidney datasets and showed that CellTrek can detect topological patterns of different cell types and cell states. They performed single-cell RNA sequencing and spatial transcriptomics experiments on two ductal carcinoma in situ tissues and applied CellTrek to identify tumor subclones that were restricted to different ducts, and specific T-cell states adjacent to the tumor areas.
BioTuring
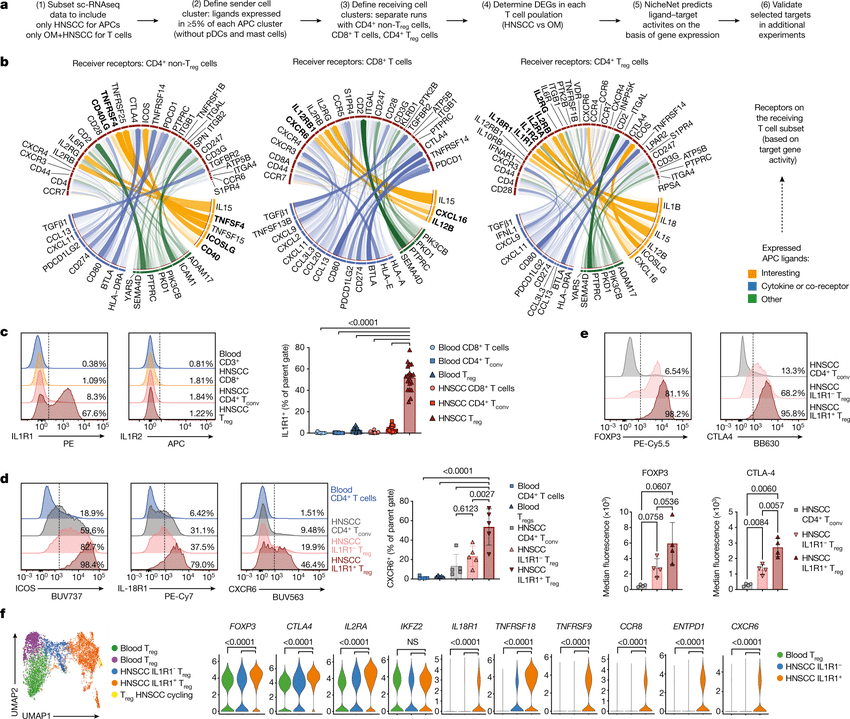
Computational methods that model how the gene expression of a cell is influenced by interacting cells are lacking.
We present NicheNet, a method that predicts ligand–target links between interacting cells by combining their expression data with prior knowledge of signaling and gene regulatory networks.
We applied NicheNet to the tumor and immune cell microenvironment data and demonstrated that NicheNet can infer active ligands and their gene regulatory effects on interacting cells.
Trends
BioTuring
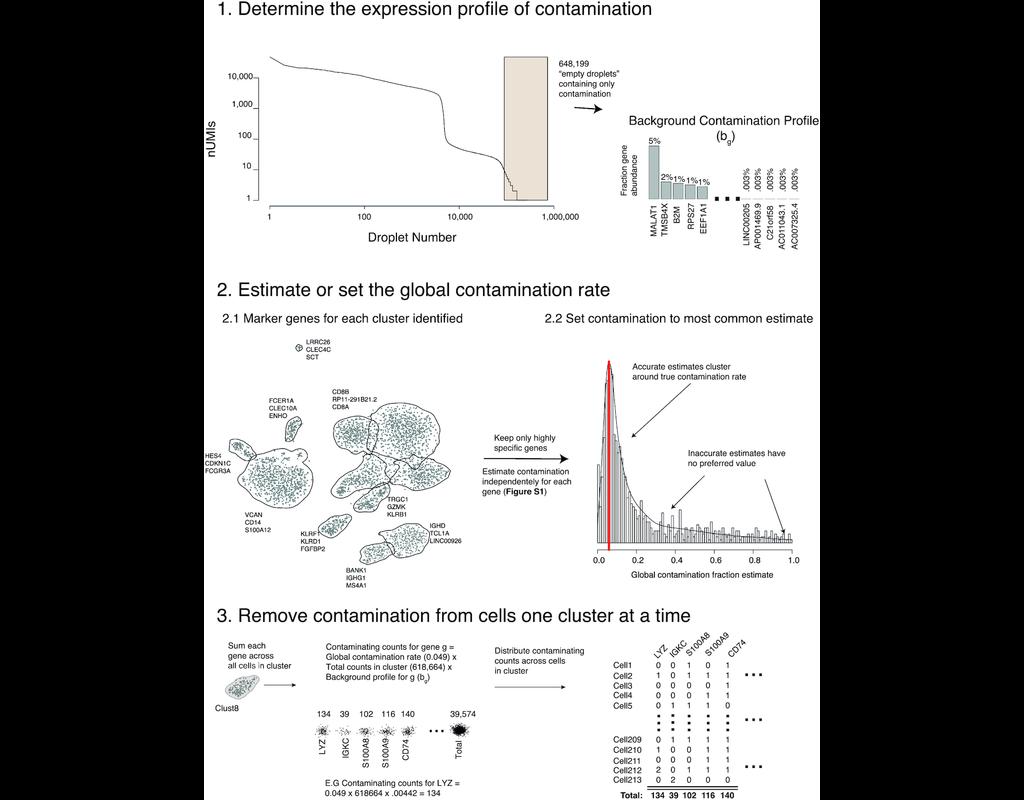
Droplet-based single-cell RNA sequence analyses assume that all acquired RNAs are endogenous to cells. However, there is a certain amount of cell-free mRNAs floating in the input solution (referred to as 'the soup'), created from cells in the input s(More)